はじめまして。Kaizen Platformのアプリエーションエンジニアの眞井(@yasu01)です。
今回は、私が2020年を通して開発してきたData Platformというデータ処理基盤についてご紹介します。
背景
Kaizen Platformの創業当時から提供しているサービスとしてKAIZEN ENGINEというものがあり、お客様のサイトにJavaScriptのコードを設置することで、サイトへアクセスしたエンドユーザーのサイト行動ログをデータレイクに蓄積される仕組みを提供しております。
そのデータは膨大で、そこで蓄積されたデータを分析することで、Site AnalyticsやLift Reportなど様々な集計を施し、これまで様々なレポートを生成・提供してきました。
データレイクからデータを整形・加工を行うステップは、何段ものETL(Extract, Transform, Load)処理となっています。
これまで、この何重にもなるETL処理は、個別の分析プロダクトやレポート毎に、個別のアプリケーションないし悪魔的な何千行にも渡るSQLによって実装されていました。
これまでの課題として、複雑な分析クエリーを都度スクラッチで書いては、都度プロダクト化していたことにあり、それによって最適なスピードで、より柔軟な分析結果をお客様へ提供できないことが課題としてありました。
これらの課題を解決するため、すべての分析プロダクトに横串に提供できるデータ処理基盤を開発するに至りました。
Data Platformは、Kaizen Platformの社内で利用しているデータ処理パイプラインです。
なぜ既成の仕組みを使わなかったのか?
既製のオープンソースのデータ処理パイプラインとして、Apache AirflowやLuigiなど有名なものはたくさんあります。
例えばNetflix社ではAirflowをカスタマイズしたMetaflowというプロダクトを提供していることでも有名です。
Kaizen Platformでも、個別のプロダクトの中ではAirflowを利用しているものもあり、その知見もありましたが、私としては当初それらの既成のシステムの検証を行った結果、Data Platformとしてはそれらをカスタマイズして利用するのではなく、独自のETL基盤を開発することにしました。
その一番の理由は、ETL基盤の利用対象が必ずしもエンジニアやデータサイエンティストではなく、カスタマーサクセスチームだったためです。
AirflowやLuigiでは、一度決めたETLやパイプライン処理をconfigファイルに設定して投入することができますが、これを書き換えることができるのはそれなりの知見が求められます。
日々、お客様と接して、そのお客様への改善策の提案を考えるカスタマーサクセスの方は、SQLは書けても、AirflowやLuigiの仕様まで理解してもらうのはオーバーヘッドコストが高いため、Data Platformでは、Kaizen Platformで扱う膨大なデータを、エンジニアやデータサイエンティストに限られないすべての社員が武器として使えるようにするために、Web画面から直接ETLの操作ができるようにする必要がありました。
また、前述のプロダクト課題を解決するため、各種分析プロダクトへも基盤として利用できるようにするため、APIから操作できるようにするなど、ETL設定を多様な手段で提供できるようにする必要がありました。
アクセシビリティという特徴
アクセシビリティとは、様々な立場の人でも利用しやすいということの概念となりますが、
Data Platformの開発コンセプトは「データ・アクセシビリティ」となります。
データサイエンティストからカスタマーサクセスまでもが利用できるように、Data Platformでは現時点で3段階の操作手段を提供しています。
- Webインターフェイス
- API
- CLI
Webインターフェイス
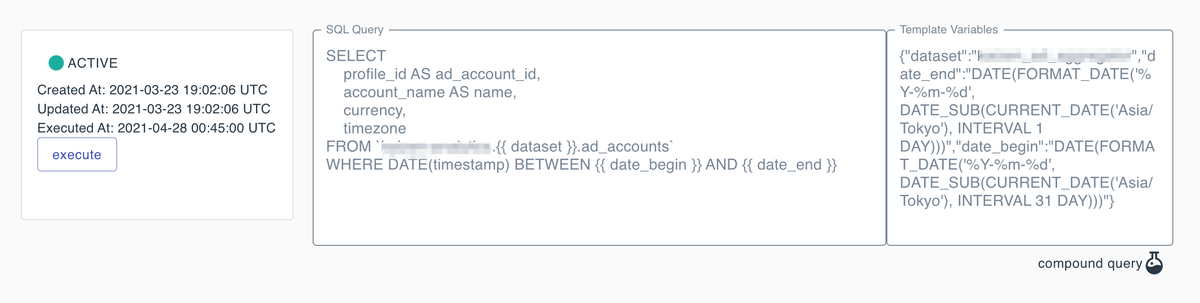
主にデータサイエンティストとカスタマーサクセスの方が画面操作を行なって、ETL設定を行うことができます。
ETLでは、データソースを指定して、データセットに対する集計クエリの記入と、実行頻度を設定することで、ETLのバッチ処理が簡単に設定できます。
ETLでは即時実行と定期実行の両者に対応しており、実行する場合によってパラメータが変わることがあるため、そのようなパラメータはクエリ変数(図1の右)として設定することができます。
またETL処理はDAG(Directed acyclic graph, 有向非巡回グラフ)の概念を取り入れ、多段式のパイプライン設定もできます。
API
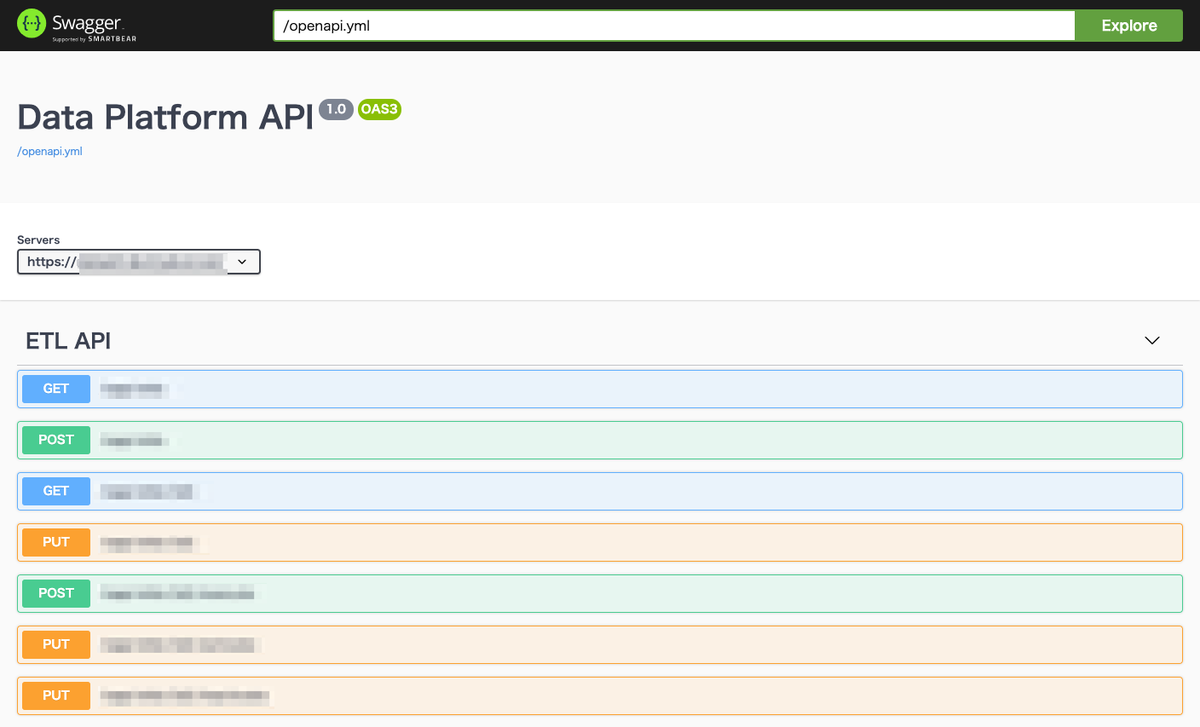
アプリケーションからETL処理を設定・実行したい場合にはAPIを介して操作する形になります。
Webインターフェイスを通してできることのすべてはAPIを介しても行うことができ、新たにアプリケーションを実装する際にも、Data Platform APIを利用することで、集計処理などを任せることができます。
これによって、今まで各プロダクト毎に集計バッチ機構を構築する必要があったのから、ずっと楽になります。
CLI
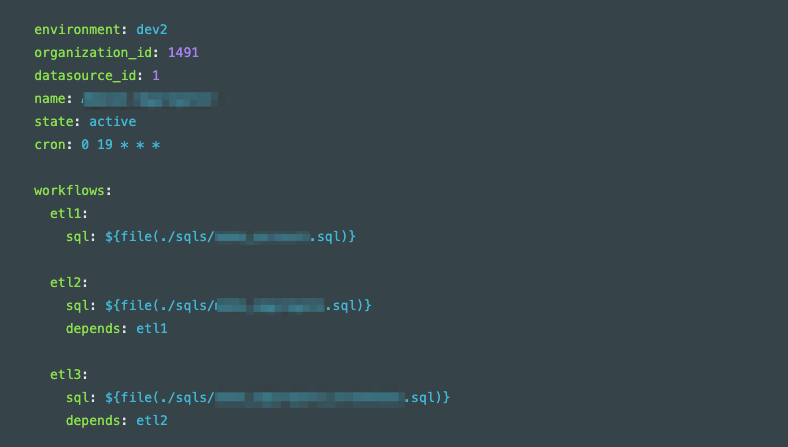
アプリケーションとして実装するほどでもなく、とはいえ複雑なデータパイプライン処理を設定したい際には、Webインターフェイスを介してすべてを設定するのが大変なの時にはCLIを介して設定する方法を提供しています。
ETL処理に必要な設定をYAML形式のconfigファイル(図3に一例)に記載してコマンドを実行することで、Data Platformへの登録ができます。
この機能を活用することで、CI/CDを介してData Platformを操作することもできます。
全体構成
Kaizen PlatformではほとんどすべてのプロダクトをReact/Rails構成で提供しており、全体のプロダクトのメンテナンスコストを下げるため、Data Platformも同様な技術を利用して開発されています。
データ処理技術にRuby?と思われるかもしれませんが、Data Platformではその全体の機構を構成するのにRuby on Railsで構築しているのに対して、データ処理の中核はSQLクエリーに任せている形になります。
SQLを書くだけでは表現が難しい複雑なデータ加工処理に対しては、独立したPythonによるETLスクリプトを現状でも実行していますが、全体のデータ処理の流れとして管理できないと不便なため、将来的にはパイプラインのカスタムモジュールとして差し込めるようにすることを構想しています。
全体感として図4のようになります。
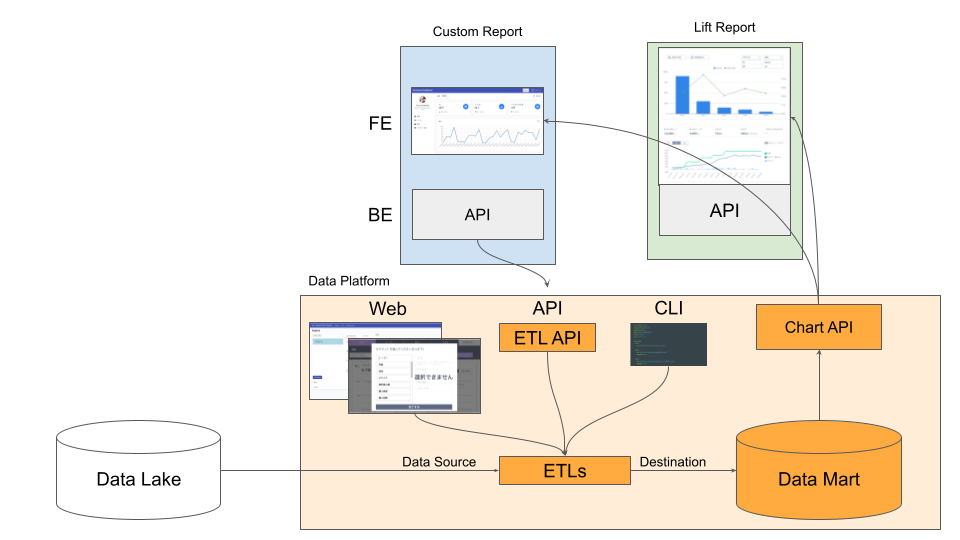
この中でもポイントをいくつかに絞ってご紹介します。
ETL

ETLとはExtract, Transform, Load処理という意味になりますが、Data Platformでは一つのETL処理を一つのモデルと考えて設計しています。 一つのモデルには、それぞれデータソースから抽出(Extract)し、加工(Transform)し、データマートに保管(Load)する処理が実装されています。
- Extractに際しては、データソースの認証情報を設定することで任意に指定することができ、そこから登録したSQLクエリーがデータソースで実行されます。
データソースとしては主にBigQueryを利用しながら、必要に応じてMySQLへ変更することもできます。 - Transformの処理の多くはSQLクエリーが担う形となっており、Data Platformとして行う加工処理はデータマートの形式に最適化するぐらいしかありません。
- 最後に、Loadに際しては、データマートとして任意の対象を指定することができるようにもなっていますが、Data Platformでは標準でデータマートを内蔵しており、SQLクエリーで抽出したデータに対してテーブルが自動生成されるようになっています。
Data Mart
データレイク、データウェアハウス、データマートなど様々な概念がデータ基盤にはありますが、それぞれはデータベースの用途の違いとなり、ここで詳述することは控えます。
Data Platformでは、データウェアハウスとデータマートを大きく区別することなく、上述のようにETLモデルを中心としながら、そのDatasourceとDestinationが指定できる形に構成することで、利用者に合わせた汎用的なユースケースに対応できる形となります。
さらに、多段式パイプライン設定をすることで、データレイク → データウェアハウス → データマートというようなETL処理を構成することもできますし、シンプルなデータレイク → データマートという形を取ることもできます。
Data Platformに標準に内蔵しているデータマートでは、上述の通り、SQLクエリーの結果に合わせて自動的にデータマートにテーブルが生成される形になっています。
データマートでは、Aurora MySQLを利用しており、一つのETLに対応する一つのテーブルが生成される仕組みになります。
データマートとして利用するに際しては、せいぜい数百GB未満のデータ量に対して、アプリケーションからの要求に対して瞬時にレスポンスしなければいけないため、ここではMySQLを利用していますが、データウェアハウスや中間テーブルとして、数百GB以上のデータ量を扱うに際しては、ETLのDestinationとしてBigQueryを指定したり、EMRを利用することを構想しています。
ユースケース
下記にData Platformを活用したいくつかのユースケースについてご紹介します。
- Custom Report
- お客様の業種毎にそのコンバージョンを最大化するために必要なサイト行動ログが変わってきます。例えばECサイトであれば、単にどのページにアクセスしたかだけでなく、どの商品に対してのアクセスであったかの情報が必要となり、KAIZEN ENGINEではお客様のページに合わせた情報を収集しています。
そこでお客様毎に異なるデータがデータレイクに蓄積されたら、画一的な分析が難しくなるため、それぞれお客様毎に合わせたカスタムレポートを生成して提供を行います。
このカスタムレポートの生成のためにData Platformを活用しています。
- お客様の業種毎にそのコンバージョンを最大化するために必要なサイト行動ログが変わってきます。例えばECサイトであれば、単にどのページにアクセスしたかだけでなく、どの商品に対してのアクセスであったかの情報が必要となり、KAIZEN ENGINEではお客様のページに合わせた情報を収集しています。
- Lift Report
- ABテストに際して改善案がどれだけコンバージョンしたかの差異を示すレポートとしてLift Reportを提供しています。
このLift Reportは、これまでディメンションを区切った集計ができなかったため、例えばPC/SP毎にどのような差異があるか、ユーザー属性として男/女や年齢層別にどのような差異があるかのディメンション別の集計が、Data Platformによってできるようになりました。
- ABテストに際して改善案がどれだけコンバージョンしたかの差異を示すレポートとしてLift Reportを提供しています。
- Amazon Data Aggregator
- Kaizen Platformは、Facebookを始め、Google, Amazonの公式マーケティングパートナーとなっていますが、Amazon広告の配信結果を集計したレポートをKaizen Adでは提供しており、この集計にもData Platformは利用されています。
このように様々な集計の機会に、BaaS的な使い方としてData Platformは提供しています。
今後の課題
以上ご紹介してきたData Platformですが、まだまだデータ・アクセシビリティの追求の上では、GUIが貧弱であったり、使い勝手の柔軟性の低さが課題としてあります。
Kaizen Platformのデータの民主化、ひいてはKaizen Platformのサービスをご利用いただいているすべてのお客様のデータ活用を通じて、世界をKaizenすることにご興味をお持ちの方は、ぜひ一緒にこのプロダクトを育てませんか?
Kaizen Platformは共に世界をKaizenする仲間を探してます!