こんにちは、AI活用研究チームのYuです。
先日リリースされた Open API の Function calling で、複数関数の同時実行を実験してみた内容を記載します。
Function calling とは
Function calling は、 関数定義をしておくとその条件に基づいてJSON で関数および変数を返してくれるものです。
Function calling and other API updates
使い方の解説はこちらのブログが詳しいです。
[OpenAI] Function callingで遊んでみたら本質が見えてきたのでまとめてみた | DevelopersIO
複数関数の同時実行
今回の実験に至ったのは、Twitterで以下の投稿を見かけたことが発端です。
工夫することで同時に2個以上のタスクの関数呼び出し(Function Calling)を実行することができたので、手法をご紹介します。
— ChatGPT研究所 (@ctgptlb) 2023年6月15日
どうやら一個上位の概念として、エージェント的な関数を作ればできそうです。
エージェント的な関数(関数を呼び出す関数)に 持っている関数名をEnum… https://t.co/VgThZdLN5r pic.twitter.com/4cJiFuSA7t
※ 先に結論を書いておくと、複数関数の実行は公式的にはサポートされておらず、今回の内容はハック的に実験したものなので本番環境への投入はオススメしません。ただ社内ツールに試験的に使ってみたり、APIの実力と限界の肌感を得るという意味では面白いと思います。
検証したユースケース
ある汎用タスクの確認をおこなう際に、サブタスクの確認と登録をチャットにやってもらうというユースケースを想定してみます。
今回は会議設定時に以下の確認質問をしてくれるようにしました。
- 日時
- 場所
- 参加者
- 議題
定義関数とフロー
- 定義関数
- set_item: item(上述のサブタスク)を登録する
- ask_next_item: 次の確認事項をユーザーに質問する
- completed_items: 全て登録が完了したらコールする
実行結果
何をやっているかが伝わるよう、先に実行結果をお見せします。
一度のAPIコールに対して、Function callingが実行される場合は2つの関数が呼ばれていることが分かります。

何をやっているか
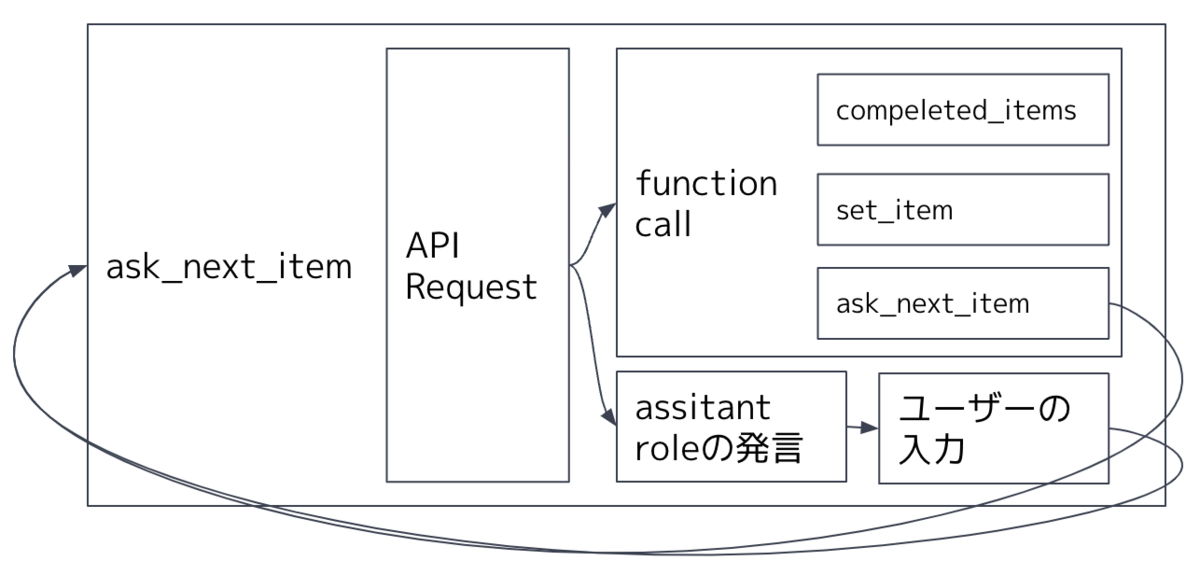
- 初回起動時に ask_next_item を呼びます。その後、
- assitant roleの発言があったら、ユーザーが回答を入力して ask_next_item を再帰的に実行
- Function calling があった場合はその関数を実行
- set_item と ask_next_item が同時に呼ばれる
- 全てのitem登録が完了されるタイミングで set_item と completed_items が同時に呼ばれる
※なんでこんな回りくどいことをやっているんだと思った方。その通りです笑。目的を達成するなら、1関数を呼ぶだけで良い設計にできます。 ただ今回の趣旨は複数関数の同時実行の検証なので、そこはご理解ください。
コード
前提として、 openai-cookbook の Utilities に記載されている関数が定義されているものとします。
functionsの定義
description = ''' - 'set_item: set into 'user_items'. - 'ask_next_item': ask user to set new item. - 'completed_items': called when user_items is completed" ''' functions = [ { "name": "chat_processor", "description": description, "parameters": { "type": "object", "properties": { "operations": { "type": "array", "items": { "type": "object", "properties": { "name": { "type": "string", "description": "name of the operation. execute as per chat_processer's description", "enum": ["set_item","ask_next_item", "completed_items"] }, "args": { "type": "object", "properties": { "key": { "type": "string", "description": "key of user_items. when call 'ask_next_item', select in order from the enum.", "enum": ['date', 'place', 'participant', 'agenda'] }, "value": { "type": "string", "description": "value of key", }, }, "required": ["key"], }, }, "required": ["args"], "description": "it contains the operation to be performed to complete user_items" }, } } } } ]
呼び出す関数を enum に登録してあるところがポイントで、こう定義しないとどうにも複数関数の同時実行ができないようでした。 この工夫は上述のツイートを参考にさせていただいております。
このアプローチは、スキーマの定義が関数ごとに明示できないというネックがあります。descriptionで自然言語である程度制御はできます(実際、ちゃんと指示すれば驚くほど高い精度で推論してくれました)が保証はされづらく、スキーマが大きく異なるケースでは使いづらいでしょう。
set_item と ask_next_item の定義
def set_item(messages, key, value): user_items[key] = value system_message = pre_system_message + " 現在の user_items = " + str(user_items) print(user_items) return [ {**message, 'content': system_message} if message['role'] == 'system' else message for message in messages] def ask_next_item(messages): chat_response = chat_completion_request( messages, functions=functions ) print("\n------------APIがリクエストされました------------") assistant_message = chat_response.json()["choices"][0]["message"] messages.append(assistant_message) if assistant_message['content'] != None: print(assistant_message['content']) user_message = input("Please enter your message: ") messages.append({"role": "user", "content": user_message + "\n 他に確認することはありますか?"}) if 'function_call' not in assistant_message: return ask_next_item(messages=messages) elif 'function_call' in assistant_message: function_call = assistant_message['function_call'] if isinstance(function_call, dict): operations = json.loads(function_call.get('arguments', '{}')).get('operations', []) for op in operations: print(f"function called: {str(op['name'])}") if op['name'] == 'set_item': messages = set_item(messages, op['args']['key'], op['args']['value']) elif op['name'] == 'ask_next_item': messages = ask_next_item(messages=messages) return messages
登録するサブタスク(日時や場所など) は user_items に格納し system role に登録しています。 set_item が呼ばれるたびに、 user_items と system role を更新しています。ただ system role の更新はしなくても期待どおり挙動しました。会話の履歴を全て投入しているので、そこから推論しているからでしょう。
ユーザーの入力プロンプトに "\n他に確認することはありますか?" を追加しているのですが、これはask_next_itemを呼ぶ確率を上げるために重要でした。入力プロンプトのままだと、呼ばれないことがかなり発生しました。
Function calling に限らず、 知識注入ではなく assitant role の次のアクションを誘導する際は system role よりも user role のプロンプトに介入する方が精度が高くなるケースが多いと感じています。
ちなみにこの関数コードはprint()の部分以外ほぼChatGPTに書いてもらいました。
system roleの初期値設定と実行
# Initialize messages messages = [] user_items = { "date": "", "place": "", "participant": "", "agenda": "" } pre_system_message = ''' - あなたはユーザーにタスクを確認するボットです。ユーザーとの会話は必ず日本語おこなってください。 - user_itemsにあるタスクについて、一度に1つずつ質問すること。例: 「会議はいつ行われますか?」 - user_itemsが完了するまで、必ず set_item と ask_next_item を実行すること。ただし、userの発言が一つもない段階ではまず質問すること。 - functionにどのような値を投入するか、勝手に決めつけないこと。ユーザーの要求があいまいな場合は、説明を求める質問をすること。 - assistantのcontentにfunction_callのようなjsonを絶対に含めないこと ''' system_message = pre_system_message + "\n- 最初の user_items = " + str(user_items) messages = [{"role": "system", "content": system_message}] # Run the chat messages = ask_next_item(messages=messages)
今回、 一番チューニングをしたのが system_message でした。
user_items は system role と functions の description にそれぞれ入れてみましたが、明らかに system role に入れた方が精度が高かったです。よく考えてみると、会話の一連の流れを考えると Function calling 時だけでなく assitantの発話にも関わるので当然とも言えるでしょう。
user_itemsが完了するまで、必ず set_item と ask_next_item を実行すること。
このプロンプトも重要で、 functions の description で指示するよりも精度は高くなりました。funcsions はあくまで function の振る舞いを定義し、どのように関数 を呼ぶかは system prompt で調整するのが良いのかもしれません。
その他
指示が複雑になってくると GPT-3.5 だと スキーマが破綻しやすくなります。今回の実装ではGPT-4でないとまともに動かなかったのですが、GPT-4でなければ動かない複雑性を自然言語チューニングに任せるのは実運用としてはリスクなので、GPT-3.5でも動くシンプルな設計にすべきでしょう。
ただこの観点は、GPT-4でfunctionsを使う際もフィジビリティテスト(どれくらい破綻せずに動くか)をGPT-3.5で行うのは、有効と言えるかもしれません。
おわりに
上記以外にも色々と細かい知見が得られました。
Kaizen Platformでは、こういったアイディアをもとにAIツールの検証やプロトタイプ開発を手伝っていただける、インターンや副業の方を募集しております。
興味がある方はぜひこちらから応募ください。まずは話をきいてみたい、という方でもかまいません!