こんにちは、AI活用研究チームのYuです。
昨今、AIツールが目覚ましい進化を遂げています。 Kaizen Platformでも、AI活用人材の育成や人材提供に力を入れています。
KaizenPlatform、国内のDXを加速させるAI-Readyな人材育成を目的に 「AI活用人材トレーニングプログラム」の提供を開始
Kaizen Platform、AIツールの活用スキルを持つエンジニアを提供する 新サービス「KAIZEN AI-READY TEAM」をリリース
AI活用研究チームでは顧客体験を改善するための取り組みも始めており、AIチャットなどの検証もおこなっています。
そちらはまだ詳細には書けませんが、チャットの仕組みによく用いられるOpenAIのEmbeddingsについて実験をおこなったので、ブログに書いてみます。
OpenAIのEmbeddings
OpenAIでは様々なAPIが提供されていますが、その一つに文章をベクトル化するEmbeddings APIがあります。
使い方の解説はこちらのブログが詳しいです。
OpenAIのEmbeddings APIのベクトルを使って検索を行う | DevelopersIO
実験内容
OpenAIは従来のベクトル化技術よりも文脈や意味を踏まえてベクトル化する精度が高いという説を耳にしたので、以下のシンプルな実験をしてみました。
- vector化し、indexに登録したい情報
- 水属性は火属性に強い
- 風属性は火属性に弱い
- 類似度を確かめたい文章
- 火属性が強いのは?
人間やChatGPTにとっては簡単なタスクですが、これをembeddingsで表現するのはさすがに難しいだろう、、というのを確かめる実験です。
今回は極力、実験や文章の記述をChatGPTに任せて見ようと思うので、ChatGPTに実験用のコードを書いてもらいました。(ChatGPTのモデルはGPT-4を利用しています)
 ChatGPTは本ブログを記載時点(2023/6月現在)では2021年9月までの情報しか参照できないため、OpenAIのEmbeddingsについて言及してくれませんでした。
こういったケースではBrowsing機能を使うと良いでしょう。
ChatGPTは本ブログを記載時点(2023/6月現在)では2021年9月までの情報しか参照できないため、OpenAIのEmbeddingsについて言及してくれませんでした。
こういったケースではBrowsing機能を使うと良いでしょう。
(せっかくなので、sentence-transformersは比較対象として使います)
以下、Browsingを使うことで期待どおりの結果が得られました。
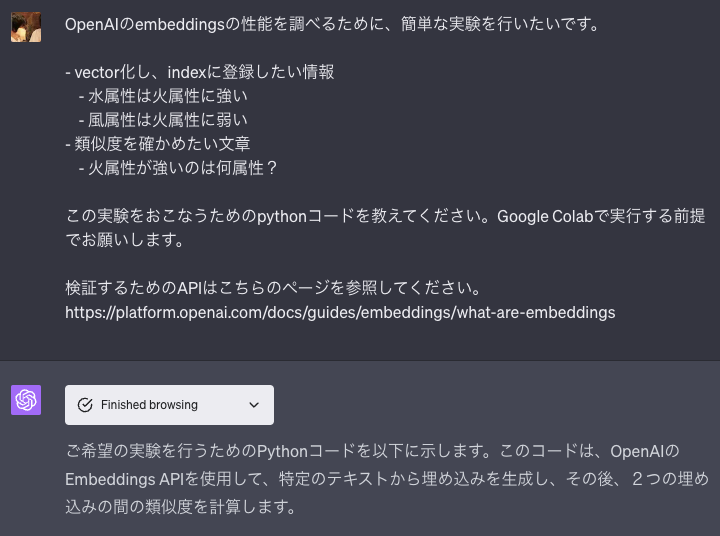
!pip install openai import openai import numpy as np openai.api_key = 'your-api-key' # 情報を登録 texts = ["水属性は火属性に強い", "風属性は火属性に弱い"] # Embeddingsを作成 responses = [openai.Embedding.create(input=text, engine="text-embedding-ada-002") for text in texts] # Embeddingsを取得 embeddings = [resp['data'][0]['embedding'] for resp in responses] # 確かめたい文章のEmbeddingを作成 query = "火属性が強いのは?" query_response = openai.Embedding.create(input=query, engine="text-embedding-ada-002") query_embedding = query_response['data'][0]['embedding'] # 類似度を計算 similarity_scores = [np.dot(embedding, query_embedding) for embedding in embeddings] # 結果を表示 for text, score in zip(texts, similarity_scores): print(f"Text: {text}, Similarity: {score}")
注) ChatGPTの出力では engine=engine="text-davinci-002" となっていたため、そこだけ修正しています。
結果は以下のようになりました。
Text: 水属性は火属性に強い, Similarity: 0.9029034091833208 Text: 風属性は火属性に弱い, Similarity: 0.8727439746715724
さすがに難しいようでした。(強いと弱いをおよそ逆ベクトルとして評価してくれたりするのかなと思ったけど、そこまではいかない)。
ここで終わってしまうのは示唆に乏しいので、比較する文章を増やし、sentence-transformersでも試してみます。
sentence-transformersの検証用コードもChatGPTに書いてもらいました。
(こちらはほぼそのまま動きました。変数は比較しやすいよう上述のコードにあわせています。)
!pip install -U sentence-transformers from sentence_transformers import SentenceTransformer, util # Load the model model = SentenceTransformer('paraphrase-MiniLM-L6-v2') # Define the sentences texts = ["水属性は火属性に強い", "風属性は火属性に弱い"] # Encode the sentences embeddings = model.encode(texts, convert_to_tensor=True) # Define the query sentence query = "火属性が強いのは?" # Encode the query query_embedding = model.encode(query, convert_to_tensor=True) # Compute cosine-similarities for each sentence with the query cosine_scores = util.pytorch_cos_sim(query_embedding, embeddings)[0] # Print the result for i, score in enumerate(cosine_scores): print(f"text: {texts[i]}, Similarity: {score}")
以下が実験結果です。意味として得たい文脈は、火が風に強いという情報です
| 比較テキスト | テキストの補足 | OpenAI Embeddings | Sentence Transformer |
|---|---|---|---|
| 水属性は火属性に強い | 得たい文脈と逆 | 0.903 | 0.942 |
| 風属性は火属性に弱い | 得たい文脈 | 0.872 | 0.898 |
| 火属性は風属性に強い | 得たい文脈 | 0.919 | 0.929 |
| 火属性が強いのは風属性 | 得たい文脈 | 0.947 | 0.952 |
| 土属性が弱いのは風属性 | 関係ない文脈 | 0.888 | 0.948 |
Sentence Transformerに比べて、OpenAI Embeddingsの方が精度が良い結果となりました。これはかなり興味深いです。
私はSentence Transformerを初めて使ったのですが、この実験から得られた結果だけで仮説を考えると、Sentence Transformerは文体や単語、接続詞のそれぞれをおよそ等価的に扱ってベクトル化しているのに対して、OpenAI Embeddingsは文脈や単語の意味を踏まえてベクトル化しているのではと思われます。
このレベルの精度が出るのであれば、ヘルプページやブログ記事などを投入した際に、かなり精度の高い探索が期待できそうです。
OpenAIでは画像とテキストのembeddingを得るCLIPも提供されており、こちらもいつか試してみたいと思います。
おわりに
Kaizen Platformでは、AIツールの検証やプロトタイプ開発、トレーニングプログラム作成などを手伝っていただけるインターンを募集しております。 興味がある方はぜひこちらから応募ください。まずは話をきいてみたい、という方でもかまいません!